Andrey Zhukov's Tech Blog
BLOG
ARCHIVE
SUBSTACK
LINKEDIN
GITHUB
STACK OVERFLOW
UPWORK
INSTAGRAM
YOUTUBE
RSS
python
2024
Mar 20
Protocol buffers organization in Python microservices
2024
Jan 27
Essential Python tools for writing quality code
2023
Jan 25
How to replace azure-storage
2023
Jan 17
How to replace oauth2client with google-auth and google-auth-oauthlib
2022
Jan 23
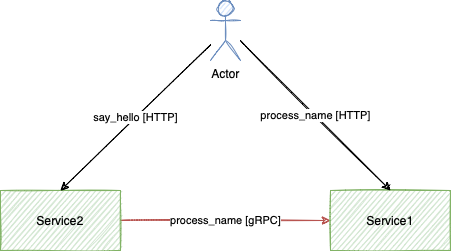
How to use asyncio gRPC in AioHTTP microservices
2021
Sep 07
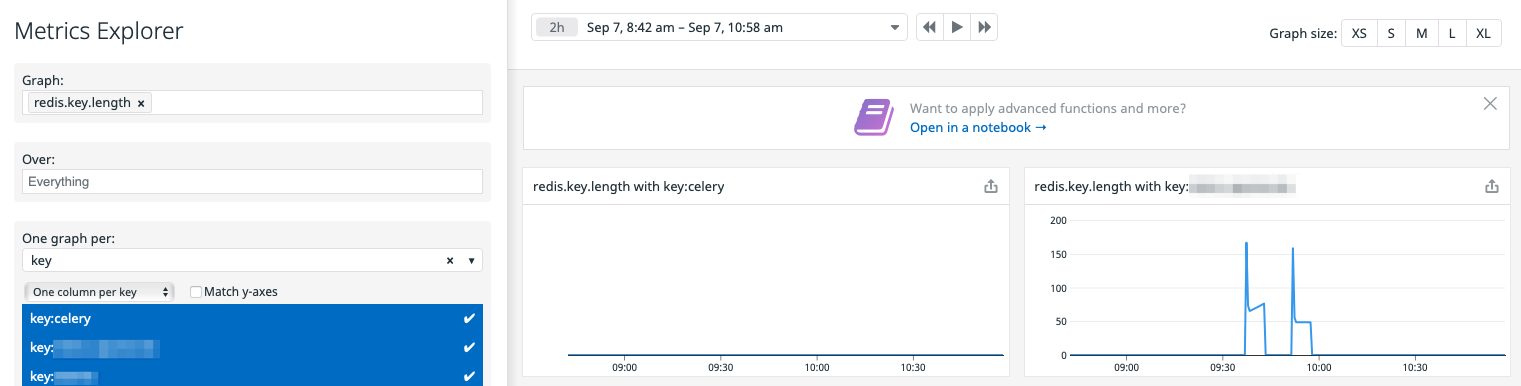
Celery queues monitoring in Datadog
2021
Aug 16
How to send celery task from async code
2021
Jun 17
How to replace celery banner with one log line
2020
Jun 06
Calling python async function from sync code
2020
May 30
VSCode settings and plugins
2020
May 23
How to set environment variables for pytest in VSCode
2020
May 17
RabbitMQ with AioHttp example
2019
Aug 15
AsyncIO REST example with aiohttp, motor and umongo
2019
May 22
Mock aiohttp request in unittests
2019
Mar 07
Get blinker signal's receivers names
2019
Jan 24
Easy charts in python app with plotly
2019
Jan 18
Mongoengine as_pymongo performance
2019
Jan 11
Celery Execution Pools
2018
Dec 11
Maximum number of client connections in Flask-SocketIO with Eventlet
2018
Dec 05
How to split Celery tasks file
2018
Nov 14
CSRF exempt for Flask-RESTPlus API
2018
Oct 18
Function as model column in Flask Admin
2018
Jul 17
Auth0 authorization to a Python API with PyJWT
2018
Jun 26
Disable user loading for some routes for app using Flask-Security
2018
Jun 07
How to decode a Flask session or a CSRF token
2018
May 30
Remote model in Flask-Admin
2018
Apr 17
Celery flower for several applications
2018
Apr 13
Celery checklist
2018
Mar 30
Microsoft Graph Api UnknownError in batch request
2018
Feb 16
Export and import for MongoEngine model in Flask-Admin
2018
Feb 08
How to disable field in MongoEngine subdocument in Flask-Admin
2017
Dec 20
No-Cache headers in Flask
2017
Dec 13
Flask-Admin authentication through oAuth
2017
Nov 29
Flask-BabelEx translations in a Celery task
2017
Nov 21
Flask-RESTPlus similar resources for MongoEngine model
2017
Sep 07
How to install pillow, psycopg, pylibmc packages in python:alpine image
2017
Aug 08
Mailgun for emails in docker
2017
Jul 28
JSON logging in Python
2017
Jul 11
Interesting articles
2017
Jul 05
Flask-RESTful migration to Flask-RESTPlus
2017
Jun 27
How to use Jupyter notebooks with Flask app
2017
Jun 20
Flask-Security 3.0.0 released
2017
Jun 16
Mongoengine sanitized string field
2017
May 18
How to refresh access token for Microsoft Graph in Python
2017
Apr 14
Migrations for MongoEngine
2017
Apr 11
How to use multiple databases with Flask-MongoEngine
2017
Mar 03
Google App Engine limits and vendor locks
2017
Feb 28
Celery background task with notifications through socket.io
2017
Feb 10
Flask-Admin formatters examples
2017
Jan 26
Fast tests with in-memory MongoDB
2015
Apr 08
strftime for datetime before 1900 year
© 2024 Andrey Zhukov's Tech Blog.