You can subscribe here.
Technical posts with code examples stays on this site.

You can subscribe here.
Technical posts with code examples stays on this site.
I have iPad Pro 11" since 2020. I use it daily. Here is why I don’t upgrade to the new M4 version.
Recently I faced 3 types of upsteam errors. It was like 2% of all requests, but it was quite annoying.
This year 1st May was Wednesday. I took another 2 days from my 9-5 job and 2 days from the weekend. The goal was to build a schedule as if I were an indie developer. The main project was to develop an idea for a new iOS app.
Several apps that help to be more focused and organized.
For accountability, I decided to publish 12-week reviews. In a month there is not always something big happening, so I start with a year quarter. Maybe I’ll transform it into a newsletter later. I’ll publish it as a YouTube video too.
In this post one of the approaches to organizing Protobuf files in microservices architecture using gRPC.
Last summer I got a new MacBook Pro M2 and decided to go with a fresh install. With my previous MacBooks, I used Migration Assistant and it worked well. But this time it was a switch from Intel and I wanted to clean unnecessary files, applications, and settings.
Here is the list of files I moved and apps I installed.
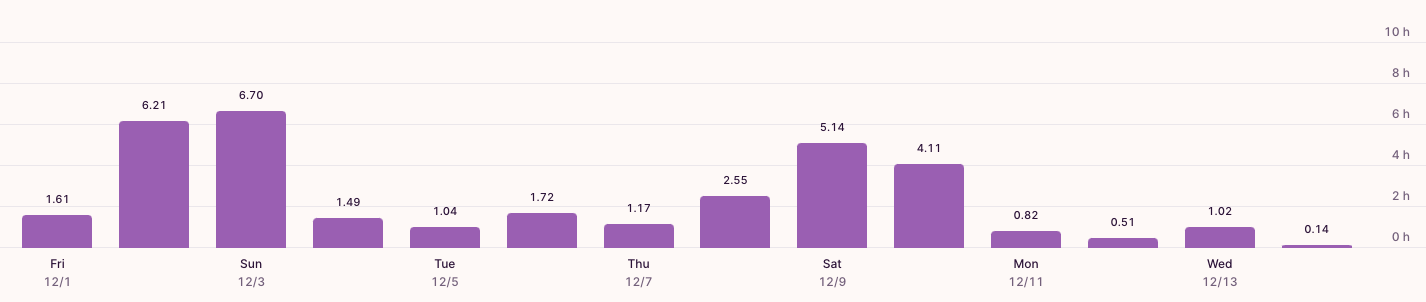
As responsible individuals, we often find ourselves prioritizing others over our own goals. If you’ve ever struggled to make progress on a personal project, this mindset change might be the key to unlocking your productivity.
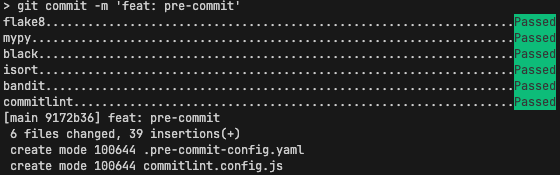
Writing quality code is essential for both personal and team projects. It helps to reduce the number of bugs, makes the code more readable and maintainable, and improves the overall quality of the project.
In this article some basic libraries that I use in everyday life.
© 2025 Andrey Zhukov's Tech Blog.